【下三滥四】解决网页无法复制问题
瞎扯
大家可曾见过以下情况?
好不容易在某个网页找到喜欢的内容,但是无法复制;被某文库网站要求收费下载……
在互联网发达的今天,这些情况比比皆是。
作为冲浪达人,我们怎能受这点屈辱?
Follow me,以下都是一些干货解决方法。
正文
I. DevTools
没错,我们首先请到了『前端开发的瑞士军刀』——浏览器的开发者工具(亦称开发人员工具)。
引用知乎文章的说法。
练手对象是我的网站,站长通过主题设置了 50 字的复制限制。
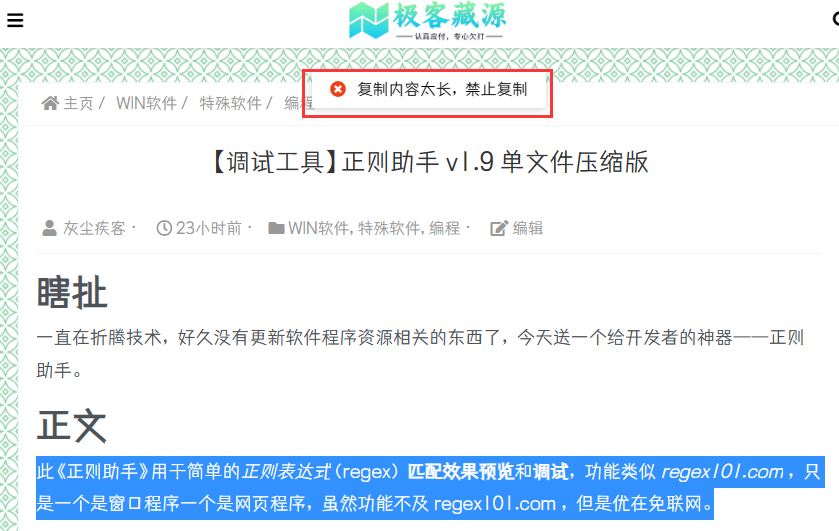
这种情况下,我们就可以通过以下方式调出 DevTools 。
-
右键文字 - 检查(同审查元素)
-
按 F12
-
【Edge】Ctrl + Shift + I
-
【Edge】右上角更多 - 更多工具 - 开发人员工具
-
……
定位到文字所在区域:
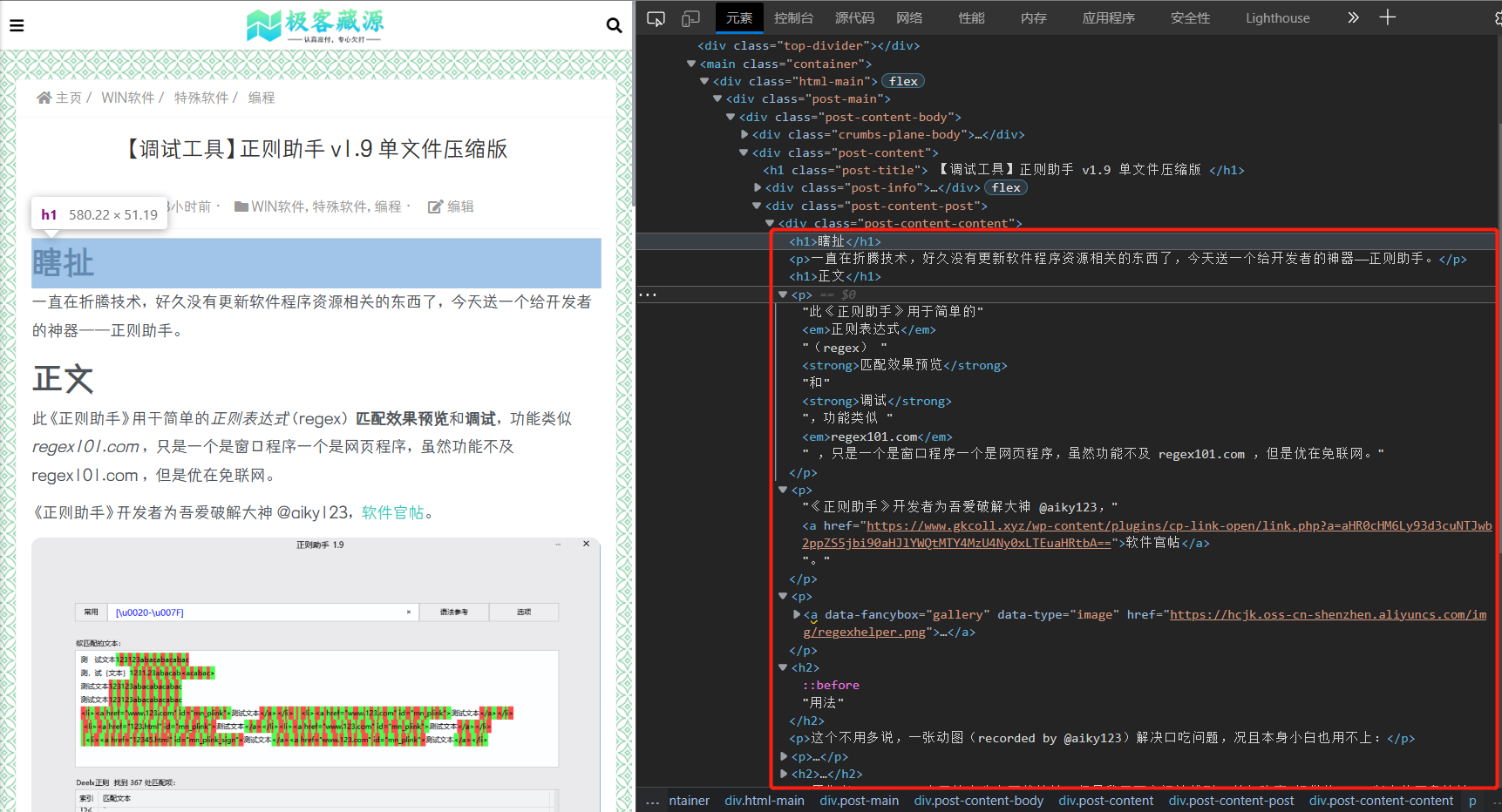
喏,你要的东西,不都整整齐齐地躺在这一个个 p 标签里吗?愣着干啥?!『C/V 大法』不就完事了?
别跟我说你连标签都不会去除,写个脚本或者查找甚至手动都能去除,还何必劳我再提供一条龙服务?
II. View Source
这个招式比较适合静态网页,但是很多类似本站的博客站(一般是动态网站)都有缓存功能(猜测的原因),致使我们可以直接在页面源码里找到内容,所以将计就计咯!
一般这个方案行得通的话第一个方案肯定行得通。
直接在网址面前添加 view-source: ,或右键-查看页面源(代)码:
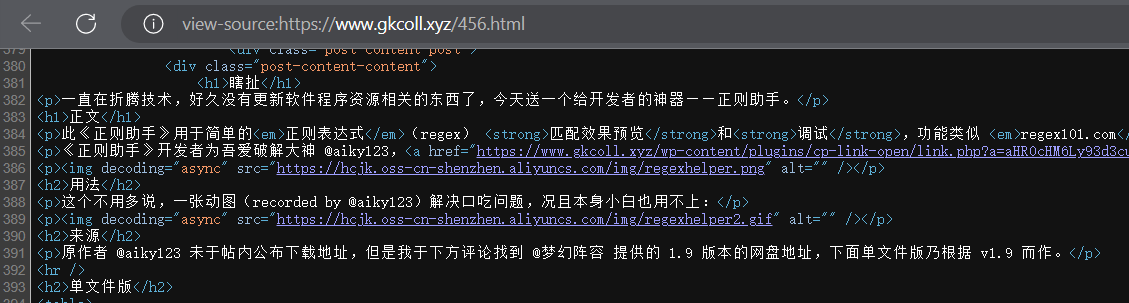
很好,它们也在等收割。
阶段性总结
以上两种方法最适用于简书和知乎。
III. 妥协
如果你遇到了一些恶心的东西,你最好还是妥协地登录账号先。
如 CSDN 中文章涉及的代码框,你瞅瞅在不登录的情况下看其源码:
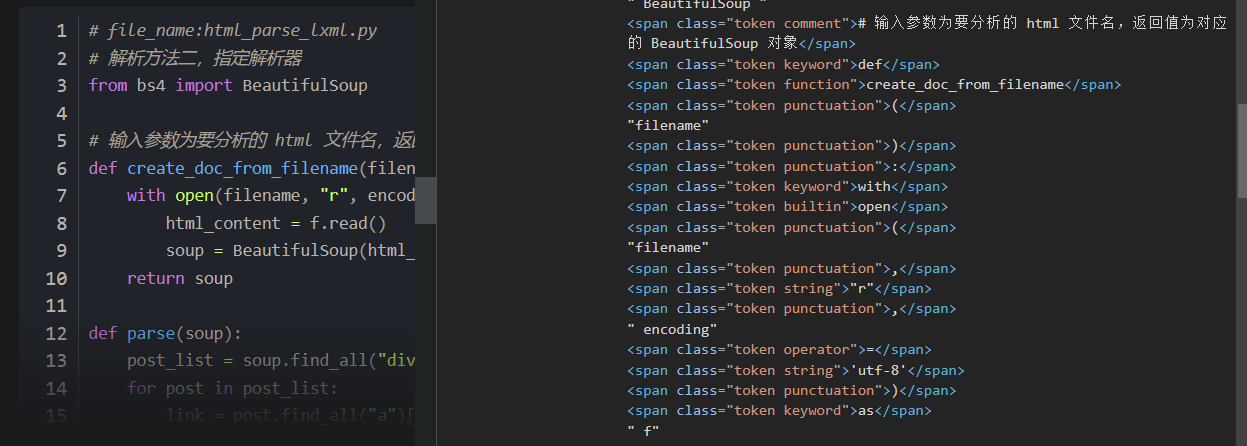
好家伙,硬生生按词分成了这么多 span 标签。
此处拿 Python 万能代码模版:爬虫代码篇_python爬虫代码大全_AI悦创|编程1v1的博客-CSDN博客 举例。
其实,登录了看也是这个效果。
但是,人家不是给了『登陆后复制』的按钮吗?就在代码框右上角。
对于此类网站,我们只需要利用我的的社交账号注册或登录后再取用。
记住,此处只是让你妥协登录,还没到要你氪金的地步。
IV. OCR 识别
各种技术发展到今天也有一定成就了,包括 OCR 技术——一种从图片中识别、提取文字的技术。
面对一些甚至是以图片形式呈现给我们的内容,我们完全可以直接使用文字识别来窃取借鉴我们想要的资源。
常见的识别方式就是腾讯大厂的两个聊天软件,专业一点的且看我恰个饭:
白描App - 图片转文字 PDF转Word OCR识别软件
价格:¥20 - ¥35.50
购买地址:https://store.lizhi.io/site/products/id/36?cid=t9fnltak开发者原价分别为 30 和 40,我给大家省钱了。
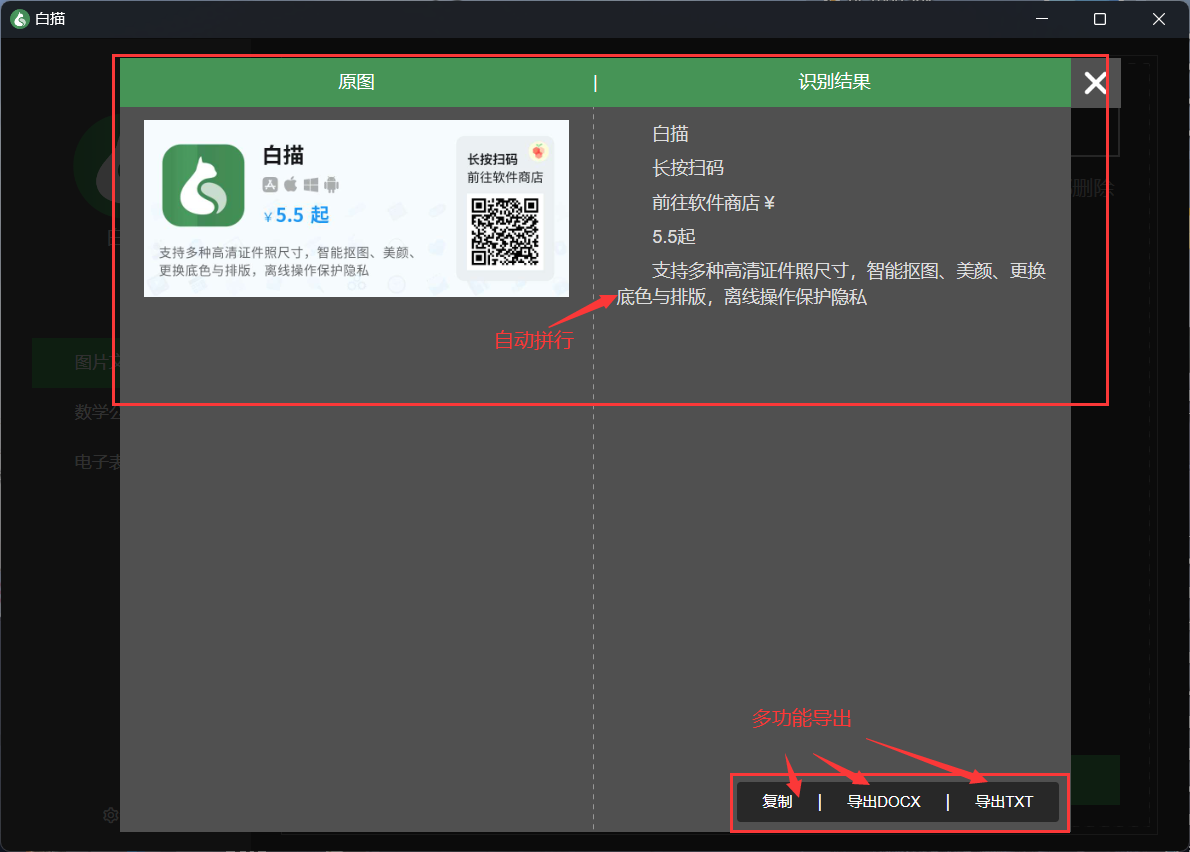
白描是一款专业的 OCR 识别软件,支持跨多设备使用,精准度超高,且能智能拼行,达到带格式的效果。(站长我当初已经 40 元入驻黄金会员)。
实际上本站早期也推荐过该利器:白描——跨端最强OCR利器 - 极客藏源。
强烈建议购买使用(黄金会员无限制,且一切付费都是买断制而不是会员制)!!!

5.5 元为白描证件照相关内购。
使用
- 打开软件后按要求上传和识别。
- 识别完成,点击查看结果
- 效果
阶段性总结
瞅瞅!这厮用在那些无良文库网站上岂不吃香?!
V. 绝路
如果遇到一些网站连预览都不给,就是硬要你通过其提供的下载方式下载或付费下载,那么这时你应该冷静,思考一下那份文件对你来说是否意义重大?
如果是,那就默念:

莽了!
如果意义不大,那就去别处碰壁或放弃挣扎。